
More Versus Better, Part III
Moving Towards Better




This is the third and final installment in a series of three essays from the Organization Science AI Task Force. Part I examined the rise in AI-generated submissions and Part II assessed the prevalence and content of AI-generated reviews. We now turn to the institutional incentives driving the trends we observed and to our thoughts on the peer review process going forward.
In Part I, we described how submission volume at Organization Science is up 42% since the launch of ChatGPT, primarily due to AI-generated text of lower quality than human-generated writing. AI-written papers are overwhelmingly desk-rejected and rarely invited for resubmission.
In Part II, we addressed how the over 30% of reviews showing some degree of AI involvement are also more difficult to read, with a narrower focus on theory over data and methods. Fortunately, editors are relying instead on human-generated reviews and their own judgment, but authors receive fewer quality reports and editors must spend more time on each manuscript.
And while each of our task force members is a regular AI user and embraces it as a research partner, our analysis suggests that AI assistance, at least in writing, does not inevitably lead to better research. Instead, it appears to generate a “more” rather than a “better” equilibrium. We now turn to the question at the root of all this: Where do we go from here?
Is Organization Science Weird?
No. . . not the editors. . . the journal. We love Org Science and think about it a lot — too much, if we’re honest. Since we released our editorial two weeks ago, though, we have heard from many of you who are thinking both about Org Science and also about the health of our whole field:
“What the field needs now is more visible examples of AI used well — disclosed in detail, evaluated honestly, and treated as a tool that earns its keep through human judgment. Bans are unrealistic. Generic disclosure boxes are theater. The harder, more useful response is showing the work and building processes, but the upside is huge if we can figure it out” (Anonymous)
“I think the crisis in peer review has long been there…. AI is just pouring oil into the fire. Too many papers, too many review requests, competing with too many other obligations…” (Anonymous)
“I think the notion of friction is especially important for understanding many of the current developments. Namely, that reduction or elimination of (different kinds of) friction(s) seems to overwhelm our systems and institutions” (Anonymous)
Since we like data1 and have fun new tools like Claude Code to help us analyze it, we scraped some of the comments on LinkedIn and coded them according to the following trusty 2 X 2: whether people thought AI in writing is a problem and whether they blamed individuals or the system:
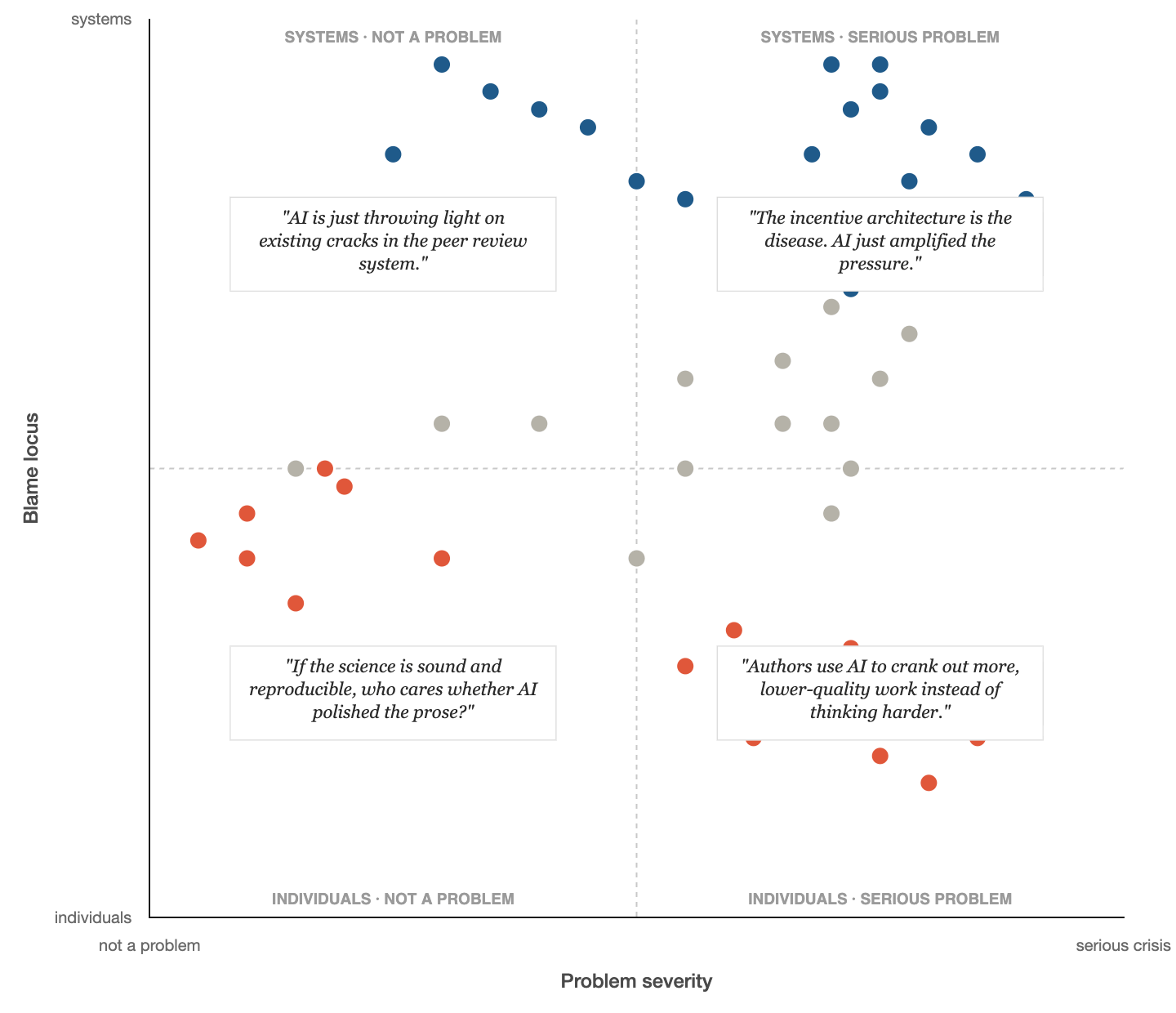
Most of the dots are in the upper right quadrant (comments that this is big, institutional problem), but there is also a wide range of views. This is good: variation implies diverse perspectives, and that is important for a robust debate.
Since we released the study, we have also heard from people outside the field of management. There also appear to be similar patterns unfolding widely across the sciences (here and here), including finance, computer science, social work research, as well as in other knowledge settings, such as book production (in our push to get out this Substack, we are sure we missed many others: send them our way so we can compile them).
So perhaps there is something else underlying all of this, something more systemic and pervasive.
Amidst these considerations, we focus on the broader institutional incentives underpinning the trends we’re observing: incentives that have been in place long before AI; incentives that will require our collective will to change.
The Incentive Problem
Research needs governance: universities have to decide who gets hired and who gets tenured and further recognized. The trouble is that research evaluation runs into two problems at once.
The first is horizontal: across fields, even sophisticated readers struggle to assess work outside their specialization: a management scholar reading an accounting paper, a sociologist reading a finance paper, an economist reading an ethnography.
The second is vertical: department committees pass promotion cases to school-wide committees, school-wide committees to provosts, and provosts to presidents and boards. And the chain continues outward from there: universities communicate their intellectual standing to peers, donors, rankers, and the public. At each step, the audience may be smart and serious, but further removed from the contextual knowledge that distinguishes one contribution from another.
One way of addressing both problems at once is hard metrics such as publication counts. The pull toward these superficially comparable metrics gets stronger as decisions cover a broader intellectual space and are aimed at a wider audience.
School rankings, like U.S. News, FT, and others, make this pull even stronger. They collapse multidimensional institutional quality into a vertical scalar. That scalar drives behavior core to the survival of our institutions: student demand, external fundraising, faculty recruiting, among others. This behavior orients tenure and promotion committees. Scholars at those institutions, in turn, shape their research toward what committees are focused on. Those scholars then become letter writers for others, and so on.
This equilibrium has always had costs but arguably has been workable because the metric—counts—was costly to produce and partially correlated with quality. Slow science reigned, and a publication in a top journal required years of work. The count arguably tracked something real.
Now make production cheap with AI, and papers emerge faster than you can say “sachertorte.” Those imperfect count signals become more imperfect. The old metrics become noisier, and the formal and normative bars for “productive” risk becoming archaic.

Testing Incentives
So far, we are just speculating that it’s not AI on its own, but instead how it collides with institutional incentives. But, how to test this? To some degree, we are all living inside this system so how do we know that incentives matter for pushing our equilibrium toward more versus better?
Not all institutions are the same. Logically, AI adoption should be most pronounced where these incentives are most acute. The introduction of the UT Dallas (UTD) list in 2005 offers a unique natural experiment. When the list was first released, we observed that some universities changed their publishing behavior soon after, with submissions to the 24 journals on the UTD list (including Organization Science) increasing significantly. Using this “shock,” we identified universities with similar publication volumes pre-UTD but divergent publication patterns after the list was released, up to the end of 2020. It is important to note that the identification of “responders” happens before our AI analysis period (2021 to 2026). We call the treatment group “UTD Responders.”
This matched pair—Non-Responders vs. a UTD Responder—was then taken to the AI era. We asked: Are “UTD Responder” institutions experiencing a stronger the post-ChatGPT surge in AI-generated submissions? The answer appears to be yes:
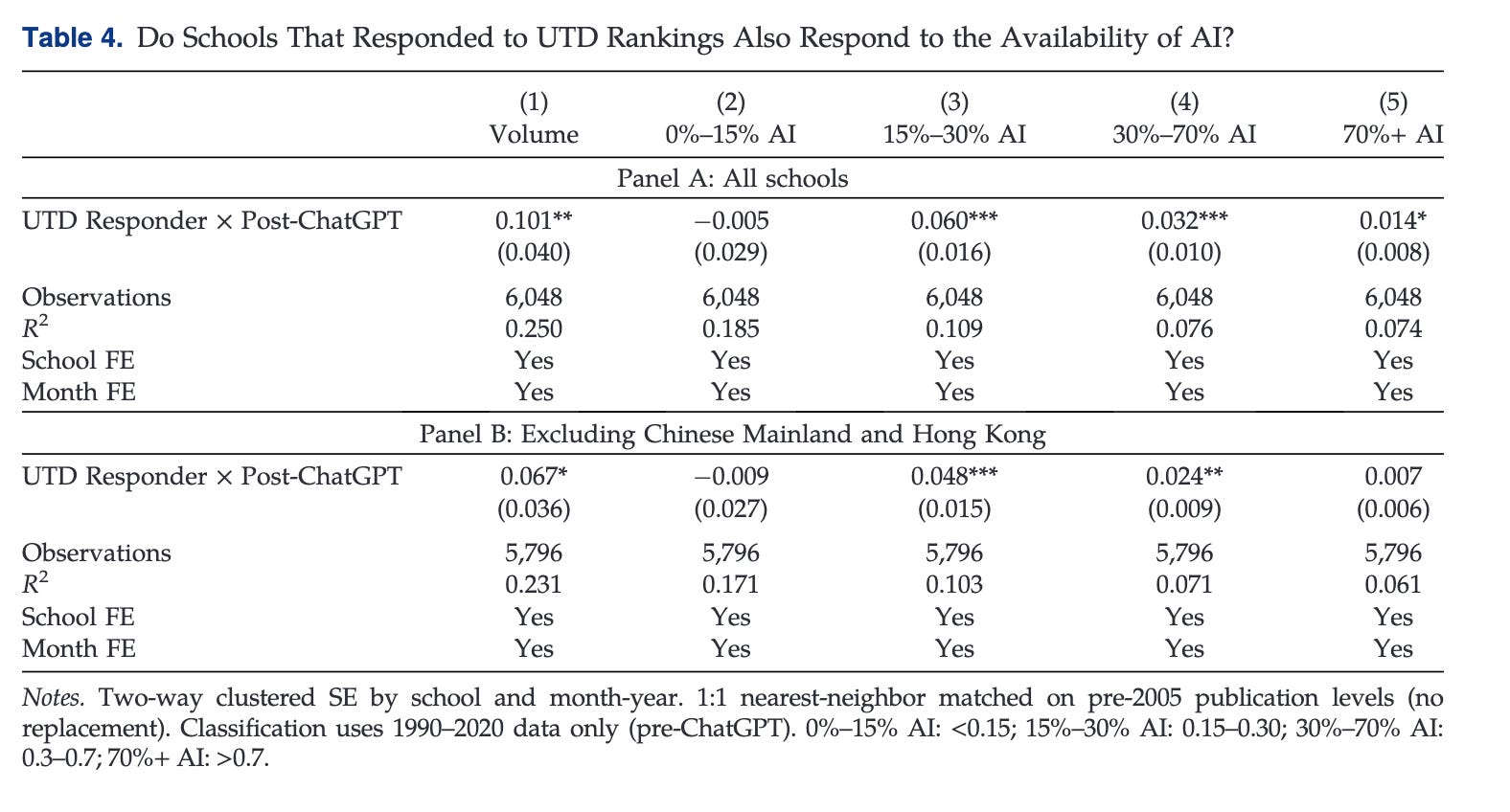
The analysis is not perfect and we did not run it to point fingers. Most of us are at institutions with strong pressure to publish. The goal was to get any handle we could on whether the incentives swirling in our field matter. No surprise: incentives matter.
Our findings are a manifestation of institutional incentives that already push researchers to both produce more. When the cost of production falls, and rewards remain constant, you get more, like, a lot more.
Does AI Use Have To Make Writing Worse?
Before we turn to what should change—a discussion that will require the collective ideas of everyone in the field and cannot be resolved on this page—it is important to note that we do not believe that AI use inevitably leads to lower quality work. Tools to automate routine research tasks (some new experiments here, here, and here—the last one including work by a member of this task force) and to help authors find weaknesses in their work (here and here) are just now being developed. We need more experiments to help lower costs AND improve quality: ideally, this should unlock a whole new terrain of research questions to explore.
Writing up research, however, is not equivalent to scraping data. Writing is a form of thinking. And writing involves friction. Sitting with that friction is where we have opportunities to draw on our collective experiences to make abstract and novel connections. This friction comes from our individual struggle to create, discussions with co-authors, and the back-and-forth with engaged editors and reviewers.
When we smooth over this friction by prompting large language models, we risk losing the aha moments that come from wrestling with our arguments on the page.
Given that AI is here to stay, it is important for us to ask how we, as a scientific community, engage with AI in ways that expand and complement our thinking rather than stunt and replace it. As a student recently said to one of us, reflecting on their own AI use, “there’s no way I was this dumb six months ago.”
Three Possible Futures for Peer Review
Based on our observations of AI use and its impact on academic writing in the post-ChatGPT era, we see three plausible trajectories for peer review going forward.
In the first scenario, we are witnessing a transitory phase and the system will self-correct over time. AI-generated papers are faring poorly in the peer review process, with editors and reviewers overwhelmingly rejecting them. As detection and screening tools improve, more of these “research-shaped objects” will be filtered out before reviewers’ valuable time is wasted. If the underlying mechanism for such submissions is, in fact, strategic, the signal from high rejection rates may even correct this behavior over time. Yet if the incentive systems are they appear (just take a quick gander at the tabs on the annual MGMT jobs spreadsheet), we may idle in this phase for the foreseeable future.
In the more dystopian, second scenario, we see a gradual erosion of the field as a whole. Submission volume continues to climb. Editors and reviewers, already stretched thin by rising submissions, withdraw from their volunteer efforts, burned out by the process. Publications lose their signaling value, and the profession retreats to AI papers aimed at AI reviewers, hollowing itself out before the systems can be reformed.

In the third scenario, institutional changes could lead to a “better” equilibrium. Here, AI will help researchers identify meaningful empirical puzzles, build rich theories, and conduct analyses that were previously impossible with available tools and methods. This pathway reflects what we believe to be the true promise of AI, even if it slows the research process. We might get papers that once took 15 years to produce, now taking just one year. This would be enable us to make explore fundamentally new territory:
“Compared to returns from exploitation, returns from exploration are systematically less certain, more remote in time, and organizationally more distant from the locus of action and adaption. What is good in the long run is not always good in the short run.” -James G. March in Exploration and Exploitation in Organizational Learning.
This trajectory is not inevitable. It requires deliberate efforts by the institutions that most visibly shape our field-level incentives: journals and universities.
What Can Journals Do?
In the near term, journals are contending with how to manage the increase in submission volume. Here, our analyses are unambiguous: the rise in submissions since late 2022 was driven by AI, and if submissions continue on this trajectory, the volunteer review system simply won’t be able to keep pace. For journals navigating this reality, there are several options worth considering, though we offer these as possibilities for discussion rather than recommendations. Many of you have also offered your own thoughts and ideas on LinkedIn this past week. We have read every comment, and please continue to write and post your ideas publicly.
First, AI tools will likely play a role. Detection tools may be useful, not as automated gatekeepers, but as a first line in helping editors determine which submissions warrant closer scrutiny before asking reviewers to invest their time. There are obvious concerns about the accuracy of these detectors, but we should be scientific about them—which ones strike the right balance of Type I and Type II errors that we are comfortable with as a field.
AI tools for review are also promising. Tools like refine.ink already help authors pre-review their papers before submitting them. There may be a future—IP issues aside—in which these same tools cover the core technical and design issues associated with a paper, freeing up reviewers to focus on areas where human judgment matters most.
Second, submission fees or caps on number of submissions per year, if carefully designed, may also play some role. Such a system will require thoughtful implementation to mitigate adverse effects, though we believe they deserve consideration as the current system asks volunteer reviewers to absorb a cost (in terms of their time) that high-volume submitters don’t have to pay.
Third, returning to how we can incentivize ambitious research that tackles bold questions and deploys novel methods, journals can do more to signal that they seek this type of work. Whether in their editorial statements, reviewer guidelines, or decision letters, journals can explicitly communicate their support for research that pushes the frontier, even if it is messier than more formulaic research, or even defies generally accepted templates for what research “should” look like.
What Can Universities Do?
While journals can help manage some symptoms, they cannot fix the underlying problem on their own.
University-level incentives have been distortionary for a while, yet the falling cost of producing submissions further accentuates their impact. When it takes days rather than months (or even years) to draft a manuscript, the gap between what institutions measure (i.e., quantity) and what they claim to actually want (i.e., quality) grows.
Tenure and promotion decisions will need to change. Existing norms that define productivity by publication counts will ring especially hollow in a world where AI can produce submissions in days. And many journals (some predatory) are rapidly increasing the volume of submissions they are accepting—often for an “open access” fee.
Somehow, universities must find a way to reward exceptional quality over quantity. This shift will require more from committees that will need to assess (and compare) intellectual contribution of scholars. Many universities balk at such evaluations due to fairness concerns and legal risks associated with increased subjectivity. Yet continuing to reward “A” (count) while hoping for “B” (quality) will only grow more problematic as the costs of “A” keep falling.
More foundational still, this problem raises the question of what the right unit of research is: a paper or something else entirely that is newly enabled by AI and helps advance and communicate knowledge. Committees should be open to experiments on this question as well.
Closing Thoughts
There is a human cost to our current trajectory. Every hour a human editor spends writing a desk rejection for a fast-to-produce manuscript is an hour spent not developing a thoughtful paper deserving of careful attention. Every review slot consumed by a low-quality submission is a slot taken from a manuscript worthy of serious engagement. Expert human judgment is now the bottleneck in a system overwhelmed by an ever-increasing number of submissions.
Whether we, as a field, move toward a “more” versus a “better” equilibrium is ultimately an institutional question. As our analyses suggest, the tools themselves are not the problem. The incentives that underlie how we use the tools pose the greatest challenge for the peer review process. Fortunately, institutions can change, though such change occurs under sustained pressure from the communities they serve.
In our efforts to bring about this change, it’s important to ask ourselves why at each step of the way.
Why do we ask the research questions we do?
Why do we write the papers we do?
Why do we do what we do?
Our plan is to create opportunities to engage with each other on these important questions, both formally and informally, so stay tuned.
Members of the Organization Science AI Task Force:
Claudine Gartenberg is an Associate Professor of Strategy at the Wharton School of the University of Pennsylvania and Senior Editor at Organization Science.
Sharique Hasan is an Associate Professor of Strategy at the Fuqua School of Duke University and Deputy Editor at Organization Science. He is the chair of the AI Task Force at Organization Science.
Alex Murray is an Associate Professor at the Lundquist College of Business at the University of Oregon and Senior Editor at Organization Science.
Lamar Pierce is Editor-in-Chief of Organization Science
. . .and evidently sending forty texts from Philadelphia at 6am CDT.